
* The human mind is based on a framework, a "world model", that contains all the information each person has about the world. Reflecting the biological neural net of the brain, the world model consists of a dynamic and interlinked "cognitive network" of abstracted ideas about the world. Humans being evolved organisms, actions taken on the basis of that network are driven and influenced by instinct and emotion.
* As a starting point in touring the mechanisms of the mind, consider the mind of Alice when she was born -- or more realistically, the lack thereof. At that moment of her emergence into the world, nothing was obvious to her about the world; it was to her a chaos of meaningless images, sounds, and sensations. She had instincts -- one of the first things she did in her life was cry in discomfort, and with plenty of good reason -- but she did not have a single specific fact about the world in her head, merely an instinctive "meta-knowledge", knowledge to acquire knowledge, to sort it all out.
By the time she was six years old or so, her observations of the world, and education by her parents, had given her a "world model" to make some sense of it all:
Dan Dennett once commented that the core question of intelligence is: "What do I do next?" At age six, Alice had a loose agenda for her days -- to get up and prepare for school, to go to school and take classes, to come home and do chores and homework, to entertain herself, then go to bed. During the day, she had to attend to personal hygiene; stay fed; deal with family, other children, teachers, and pets; to try to follow along in classes, work on homework, and pursue her personal interests. She had acquired habits -- "IF this happens, DO this" -- to deal with events, and some ability to think things out, when things weren't straightforward enough to be dealt with by habits.
Her world model was the framework of her mind, absolutely everything she knew; if it wasn't in her world model, by definition she didn't know it. Her world model told her what she needed to know to basically get along in life -- put dramatically, to survive. If she couldn't recognize hazards, her parents wouldn't dare let her out of their sight; if she couldn't spot opportunities and have some idea of how to exploit them, she would in turn be entirely reliant on her parents, to spoon-feed her everything she needed.
In reality, a healthy six-year-old can function without continuous supervision. As Alice grew older, she would learn more about the greater world, and acquire more independence, as she was educated -- being an intellectually-engaged person, she would learn far more -- but at age six, she was only really concerned with the world at hand, what is sometimes referred to as the "manifest image": "What you see is what you get."
BACK_TO_TOP* The world model in the mind is a network built up of bits and pieces. Humans are highly vision-oriented -- strongly reliant on sight, much more so than, say, smell. We know about things mostly to the extent that we have seen them. However, sight has more limitations than we generally assume it does. We believe we perceive a world of enormous detail around us, but our eyes only have high resolution in the center; we build up a detailed image of an object by scanning over it. Our vision system is like a dual radar system, with a wide-area radar having poor resolution augmented by a narrow-angle radar in the center having high resolution.
In addition, as demonstrated by the phenomenon of change blindness, we only use, and sometimes retain, what seems important from our vision. Suppose Bob goes into the kitchen; he's perfectly familiar with the place, knows where everything is, right down to which cupboard shelf he keeps the bottle of painkillers on. When he comes back into the living room, Alice asks: "Tell me what the kitchen looks like."
If he closes his eyes, he can only with effort describe what's in the kitchen, and he can only describe it a piece at a time: "There's a set of drawers next to the refrigerator."
"How many drawers?"
"Five, maybe six. They're of different heights."
"Which are tall and which are short?"
"The bottom one is tall. I think the others above it are all short."
"Let's go check."
On inspecting the kitchen, Bob says: "Oh, I was wrong -- yes, the bottom drawer is taller than the others above it, and the others are all the same height, but there's only four drawers total."
"Do you have any idea why you didn't know the number of drawers?"
Bob, who tends toward the literal-minded, accordingly tends to be a good reporter, and after thinking it over, says: "It wasn't something I needed to remember. I usually only use the top drawer, sometimes the bottom drawer, the other two little or not at all -- there's little or nothing in them, in fact."
This failure to actually notice things in our field of view is called "inattentional blindness" or "perceptual blindness". Of course, sight is one of the most significant human senses, but it isn't the only one. As with sight, all our senses are much more selective in their workings than we are inclined to think they are. If we don't notice something, we don't notice we're missing it. Distracted, Alice may not hear something perfectly audible to Bob; she may think she smells say, gunpowder, but nobody else can smell it; she may not notice minor cuts and the like, and not recall later how they came about.
We perceive the world, but how much do we actually know of it? If Alice thinks of the word "cat", she knows what a cat is, but doesn't necessarily think of any specific sort of a cat, or any detail of a cat. Working from that general idea of a cat, she can visualize instances of specific cats, for example Ella -- but Alice only has a general idea of Ella in turn. That general idea then can be broken down into specific attributes of Ella; for example, Alice knows Ella has unusually large ears.
Dennett liked to suggest: "Imagine a pirate." That done, then he asks: "Does he have a peg-leg? Which leg? An eye-patch? Which eye? Is he armed; and if armed, with a cutlass, or pistols, or both? Does he have a parrot on his shoulder? Can you see his belt?" No; if asked to imagine a pirate, everybody starts with some vague notion of a pirate with next to nothing in the way of details.
To be sure, under questioning some people will make up the details as they go along, and not notice a problem with that -- but it's not hard to show they're making things up. For example, a researcher could ask a subject to inspect a drawing of three pirates, with different features, clothes, and accessories. The drawing is then taken away, to be replaced by a drawing of, say, three clowns, which is inspected in turn. When the picture of clowns is taken away, the subject is queried for specific details about the pirate picture. Most will not score much better than they would if they just admittedly made guesses.
Neuropsychologists like to call the neurons handling an individual pattern in the brain -- a cat, a pirate, whatever -- a "patch". We might more broadly call a single pattern stored or moving through the brain an "abstract" -- as in the very brief summary that precedes a paper in a technical journal. The brain stores knowledge of a tremendous number of details of the real world, but to achieve that capacity, it has to be "parsimonious", storing only as much as needed about any one thing. That's why we have a head crammed full of abstracts.
Everything we can think of is encoded in the brain as an abstract. Each is unitary; it's the one thing we are thinking about at any moment, though it may be linked to a set of details. We have an abstract of a pirate, which may be linked to abstracts for a sword or a peg-leg or a parrot, or all else piratical.
Consider symbol recognition. Those of us raised to use the roman character set recognize the symbols instantly, even when they're rendered in cartoonish fonts, and can write them without a second thought. However, if Alice tries to visualize the letter "A" in her mind's eye -- okay, she can do so, but it's not like there's a picture of in her head. What kind of font does it use? What color is it? There's nothing there but an abstract; as Dennett might have put it, it's "sorta" there and "sorta" not, Dennett having been fond of his "sorta" operator.
Consider a more elaborate example of symbol recognition: Chinese ideographic characters, the "hanzi" -- or "kanji", as the Japanese call them. There's a set of a few hundred basic characters, or "radicals", with all the other characters being composites of two, three, or four of these radicals. The most elaborate characters may have dozens of strokes; different characters may share radicals, making them hard to tell apart.
To recognize hanzi characters, Alice ends up learning to recognize the combination of radicals and their arrangement. To really learn the characters, she also has to learn their "stroke order" -- to be properly written by hand, they have to be sketched in a precise order. Once Alice knows the stroke order, she then fully knows the character, being able to draw it out accurately stroke-by-stroke. This is because the abstract in her mind for each character is reduced to its essentials, simply a set of lines and their arrangements.
* The same principle of abstraction shows up in facial recognition. Humans readily identify the faces of others, with a substantial component of brain wiring clearly dedicated to the task. However, we don't really retain a picture of anyone's face, so much as a set of attributes: hair color and length, skin color, general shape of face, size and layout of features, and so on. When we see a particular face, we do obtain an image of it; but if we close our eyes, we only have a vague abstract of the face. We may zero in on particular features, but they're abstracts in turn.
Caricaturists lampoon public figures by exaggerating their features in drawings; some people who don't have features much off the norm are hard to caricature, hard to recognize. Incidentally, there are people who recognize faces poorly or not at all, a condition known as "prosopagnosia". It is generally associated with damage to the "fusiform areas", on the bottom of the temporal lobes of the cerebral cortex.
Not at all incidentally, in 2017 researchers from the California Institute of Technology published breathtaking research on face recognition in monkeys. Cognitive researchers already knew that faces trigger strong neural responses in specific regions of the brain called "face patches". The Caltech researchers spent years mapping the activation of different face patches to facial features to facial features like eye size and mouth length.
In support of the study, the researchers developed software that could break down faces sampled from images into 50 different traits or "dimensions" that characterized the faces. None of the dimensions actually corresponded to particular facial features; instead, half took into account characteristics related to shape, such as the distance between a person's eyes, or the width of a hairline; while the other half took into account features like skin tone and texture.
Equipped with the dimension data, the researchers inserted electrodes into the brains of two macaque monkeys, then monitored how 205 face patch neurons responded to thousands of computer-generated human faces that varied across the 50 dimensions. From the flood of data, they used software to sort out the firing of neurons relative to the dimensions of each face, ultimately mapping out the correlation between the two.
Using the firings of specific neurons, software could reconstruct the face, with test subjects able to match the reconstructed face to an actual face 80% of the time. The result of the experiment almost suggested the ability to see the pictures in a monkey's brain -- but that's precisely what it did not do. It picked up firings of sets of neurons, each set encoding an abstract corresponding to an aspect of a face, and then reconstructed each set into face images using computer software.
The brain does not store pictures as such, it stores abstracts -- or more usually, hierarchical sets of related abstracts -- that can be reconstructed into pictures. If Alice were adept at drawing, she could draw a face from memory, but it wouldn't be like she was copying from a picture she saw in the Cartesian theater of her head. She would instead construct the drawing one element at a time, starting with the general shape, then working down to the details. She never really sees a picture in her head; she just knows the bits and pieces of one, and literally realizes the face as she draws it.
BACK_TO_TOP* The mind's abstraction of the world is well understood by designers of virtual-reality simulations. Trying to simulate the world in full detail isn't practical -- in fact, it's impossible. An attempt to simulate an entire world is defeated by a "combinatorial explosion" of details that, as we attempt to probe more deeply, overwhelms the simulation.
If the simulation were to feature a bookstore, for example, would it have thousands of books that could be accessed, each with its own texts and illustrations? Or for that matter misprints, stains, torn pages? If there were a supermarket in the simulation, would it have all the products, with their packaging and contents? If there were a lawn, would it detail each unique blade of grass? If a tree, each leaf? How far would it make sense to go? The designers have to draw the line someplace. Go into a bookstore in a simulation, none of the books can be accessed.

VR simulations necessarily economize by neglecting elements that aren't important to the goals of the simulation, leaving backgrounds and such in a stylized state, to focus on the important details. In much the same way, an animated video will generally downplay background details, there being no great need for them to carry the story along; indeed, in cheaper animations, the background may be a minimalist still image, hardly more than a stage set with a few stylized and static props.
More expensive animated productions will have detailed backgrounds, often with sly little sight gags to entertain the attentive. In a live-action video taking place off set in a real-world environment, the background detail comes along for free -- but just as in the real world we experience on a daily basis, we don't pay the background much mind. Disruptive distractions from the background are typically edited out in the production process, or force a reshoot of the scene.
If we had any simulation that could always be resolved into as much consistent detail as we care to look for, it would be indistinguishable from reality, and we would have no alternative but to accept it as reality. It is simply not possible to build such a detailed simulation, since it would require unlimited resources.
Dennett once commented that reports of hallucinations that "felt real" had to still be illusions. Hallucinations can be seen as self-created virtual realities; and just like VR simulations, they're fakery, lacking in detail. Any hallucinatory vision that comes out of nowhere will have one, or possibly a few more, elements that are vivid, with everything else left fuzzy. If Alice has a vivid dream, the vividness only indicates that the vision made a strong emotional impression on her. People who have near-death experiences may insist that the NDE felt too real to be dismissed as a hallucination; but that's no more than saying: "It must have been for real, because I'm convinced it was for real."
If the apparent realism of vivid hallucinations is an illusion, then why isn't the perceived realism of the material world an illusion as well? To be sure, except for people who are delusional or afflicted by hallucinations, our world model was derived from and is grounded in the material world, which is not altered by changes in our mental state. It's just that the world model ends up being a quick and selective sketch of what we "need to know", or at least want to know, that overlooks most of the detail. Sometimes the details can be important; and sometimes we get important details wrong.
BACK_TO_TOP* The world model is, of course, not static, being adjusted as the world changes around us; along with the three space dimensions, it has a time dimension. The current state of the world model is compared to previous states, stored in memory. Alice retains a history of her past life -- but that history is clearly even more subject to illusions than her immediate perceptions.
We only have one memory at a time, memories being accessed one after the other, and not in all that orderly a way. Our memory is "associative", in that perceptions, or memories, cue memories. If we see or remember a black cat, we think of Ella, another black cat we once knew. We are always getting cues, with memories being recovered accordingly, mostly being discarded unless they seem significant. We can also recover memories at will, for example when we need them for a task at hand, for example recalling a phone number or a computer password.
Retrieval of memories, however, is not entirely reliable. In modern society, we have heads full of passwords and account numbers, and it's only too easy to get them scrambled, or simply forget those we don't use very much. Memories do get a degree of priority from how recent they are, their perceived significance, and how often they come to mind; but there's no saying we can retrieve a memory when we need it. Sometimes we can't remember a password, even if we normally can -- to have it then pop into the head later.
In addition, usually when we're idle, we sometimes we get memories that don't seem to be prompted by anything. For example, we might remember something that happened years ago and had been forgotten, to then be recollected for the first time in decades, out of nowhere. On the reverse side of that coin, we may have unpleasant memories that often come to mind that we wish to forget, but we can't suppress. Indeed, trying to do tends to reinforce the memory.
While our memories get stronger with access, they still never become completely reliable. Bob is a disciplined fellow who performs a set of several dozen different exercises in a daily session -- but though he's done it for years, he still occasionally scrambles the sequence of the exercises, or drops one of the exercises. The daily repetition may actually confound memory, in that he does a particular exercise, and then doesn't remember if he did it just then, or the day before.
One of the big differences between the brain and a computer is that the computer is "synchronous", in that its operations are controlled by a clock pulse train, stepping from one instruction to the next in cadence with the pulses -- in a way comparable to the methodical stepping of gears in a mechanical clock. At a higher level, the computer synchronously keeps track of time and date using a "system clock". If files are created in a computer system, they are stamped with time and date, obtained from the system clock; and the system similarly keeps track of important events in "log files" that record the events along with the time and date they happened. The computer can also be programmed to take specific actions on particular future times and dates.
The brain, however, is "asynchronous", not rigidly stepping through a sequence of operations like a clock, and it certainly doesn't have a system clock. The brain's loose and irregular sense of time is why we wear wristwatches and keep calendars. Our memories aren't "date-stamped" like a computer file, so it can be hard to know how old a memory really is. When one gets older, the past tends to become jumbled together, hard to keep straight. We tend to construct a consistent "story" of events in our lives -- maintaining a sense of continuity to the present "now" -- by piecing together memories that may not actually be as correct, complete, coherent, or consecutive as we think they are.
We only remember a small portion of that which happens to us; it's not like the brain stores a continuous recording of our every waking moment, it only stores highlights, abstracts of the events. Of that which we do remember, we may later forget, and the older the memory, the more likely it is we'll forget; or recall things incorrectly; or sometimes get memories crosswired; or just make them up. Some of our memories are false -- indeed, as studies in "regression hypnosis" have demonstrated, it is also not difficult to create fictions, and then persuade test subjects that they remember them as having happened.
There is no such thing as a photographic memory; it's a fiction, an imagined album of image frames from a Cartesian theater that doesn't really exist. To be sure, some people have astounding memories, but in no case is there an actual picture of the world stored in the brain. It's just that some have an enhanced skill to inventory detail in a scene, and remember it much better than others. There are a few rare people who, if given a drawing of three pirates, will inspect it obsessively, and be able to remember the details.
BACK_TO_TOP* The abstracts making up Alice's world model are extensively linked together, forming "cognitive networks". Just as any one neuron in the brain does very little, any one abstract is of little use as well. The brain acquires its powers through the organized interconnectivity of its vast numbers of neurons; and in the same way, the abstracts of the mind get things done through their organized interactions.
As a starting point for cognitive networks, consider the map of the London Underground -- the Tube, subway system. In 1933, the London Passenger Transport Board was established to consolidate a disorderly network of subway and bus lines. The exercise was to a degree one of establishing common cosmetics, to give the system a common style. One aspect of that effort was to develop a universal transit system map.
Up to that time, transit system maps had been like street maps, being scaled-down two-dimensional depictions of the geographical layout of the system. One Harry Beck (1902:1974), an engineering draftsman, realized that was the wrong model: all passengers of subways or buses needed to know was where the stations were and what interconnections existed between them. Other than a general notion of length and direction, passengers had no need to know the exact twists and turns of a route.
Beck came up with a map reduced to a network, with the stations marked as "nodes", and the routes drawn as straight or diagonal lines, or some combination of them, connecting stations. The London Underground map reduced a messy real-world map to a set of links, connecting the nodes, the stations, in the network. Each node was linked to the nodes leading to it, its "predecessors"; and the nodes following it, its "successors".
Passengers took to the map immediately, since it was so much easier to interpret. It was a closer match to basic human cognitive processes, eliminating extraneous detail. We effectively use such abstracted mental maps like that all the time, to get around the house, to get around town. The Underground map also matched human aesthetic preferences, being printed in an appealing geometric and colorful style.
Beck's minimalist map both defined and reflected the cognitive network that Londoners used to navigate the Tube system. To be sure, the map itself was no more or less than a representation; the cognitive networks of subway riders were much more elaborate -- for a significant example, associating stations with facilities of interest near to them. Modern transit system maps trace their ancestry back to Harry Beck's map.
In any case, there's nothing more to a cognitive network, any cognitive network, than its nodes and links, encoded in the brain's neurons. All neurons do is store and match patterns; they store memories and establish links from one to another. From these simple behaviors of neurons, linked into networks, all the human brain's capabilities emerge.
* For a basic example of a cognitive network in operation, suppose Bob is playing the classic Russian computer game of Tetris. He learned the rules of the game by reading up on it, or being shown by a colleague, and then tinkering with it to see how it works.
The game is played in a rectangular vertical grid, with one of seven "tetrominoes" -- different arrangements of four blocks -- falling at random from the top to descend towards the bottom. Bob can move the block back and forth with the keyboard arrow keys, and rotate it by hitting the keyboard space bar. His goal is to fit the tetrominoes together when they hit the bottom of the rectangle. If he can form a solid row of blocks across the rectangle, the row disappears, and he scores points. Any incomplete rows stack up from the bottom, until there's no more space to permit tetrominoes to fall, and the game is over.
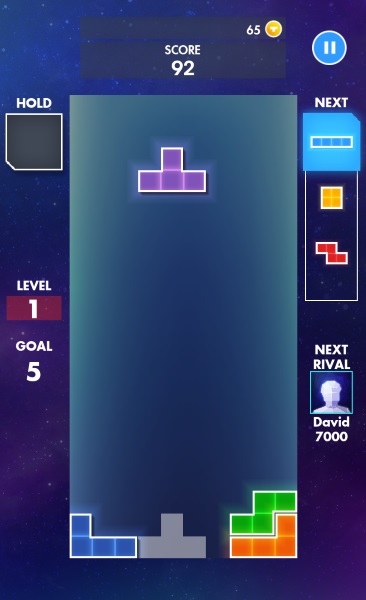
Bob works in a cycle through the game. He sees a tetromino falling from the top of the grid, trying to match the pattern for a fit into the stack below. Cued by the match, he presses the arrow keys to move the tetromino to the right position, and presses the space bar to change its orientation. Once it's in place in the stack, he evaluates the stack to see opportunities; then handles the next tetromino falling from the top.
As he acquires experience, he devises refinements to his gameplay, such as what to if he has more than one option for plugging in a tetromino -- which one is best? -- or if he has no very good options. Over time, he becomes increasingly adept at the game, reaching high scores he couldn't have achieved at the outset. If he's fallen behind the learning curve and the stack is rising towards the top of the playing grid, he doesn't have time to plan any more, he just unconsciously works by reflex and hopes for the best.
The bottom line is that Bob plays the game through an interconnected cognitive network that includes:
There's nothing magical going on here -- it's entirely consistent with the operation of neurons. To be sure, this is about as simple and straightforward as a useful example of a cognitive network could be, though with the caution that the learning process by which Bob picked up Tetris is not trivial.
In practice, cognitive networks may be much more elaborate, and not so well-defined or complete. It should also be emphasized that cognitive networks tend to be variable, changing over time as new elements are added, new connections are established, or old elements and connections are forgotten.
Dennett believed the construction and maintenance of cognitive networks reflected a "multiple drafts" model. A cognitive network, as it first arises in the mind, may well be incomplete, the network being modified as elements and connections are added, changed, or deleted. If Bob witnesses an accident, he has a set of perceptions that he may not tie together until later, and then he may get it wrong, for example scrambling the order of events. Even if he gets it right at first, later he may inadvertently break it when he recalls it. The story is always open for revision, and the revisions won't necessarily improve the accuracy of the memory -- instead, gradually mangling it over time.
BACK_TO_TOP* The mind is rooted in instinct and emotion. Just thinking is useless if we don't actually want to do anything in particular; we have to want to do things, and our wants are based in emotion, driven by instincts. We feel hungry, we want to eat; we feel curiosity, we investigate; we feel boredom, we find something to do; we feel fear, we want to protect ourselves. Feelings are not the same as thinking, but they drive our thinking.
Emotions are derived from what are called the "paleocircuits" of the brain -- ancient fixed neural pathways in the spinal cord, brain stem, and forebrain that we share with our distant ancestors. Those paleocircuits may be activated by physiology -- pain, cold, heat, weariness -- or perceptions of events -- dangerous things happen to us, we instinctively react in fear or anger. The instinctive reactions may involve both the generation and reception of neurotransmitters that alter the brain's function from its normal state.
Our instincts don't tell us much in specific, it's more like they just tell us: "Go that-a-way!" -- without providing any more than a vague sense of what "that-a-way" means. In practice, it's hard to sort out what is instinct from what we have been educated to do, a confusion known as "nature versus nurture". Some believe that nothing can be attributed to nature, that all human behavior is due to nurture, but that's an extreme and unpopular point of view. It is true that humans don't have instincts like those of, say, a spider, genetically preprogrammed to spin a web, but we still need a certain amount of instinct just to function.
Suppose Bob were to wake up in the control room of a giant robot. He can see and hear the outside world, but it's too dark inside the control room to see anything. He knows there are controls in the room, but he doesn't know where they are, or how to get them to work if he did. We're really not in any different situation in controlling our own bodies; if we didn't innately know how to move our limbs and take other actions, we wouldn't survive.
Were we trained to have emotions? Animals have emotions too, anybody who owns a dog knows that, and it's very difficult to believe those emotions were trained into them. Indeed, different breeds of dogs tend to have different emotional temperaments -- for example, the notorious geniality of golden retrievers.
It is certainly true that the manifestation of instincts is heavily influenced by nurture; we have a sex drive, but our sexual preferences are highly idiosyncratic, just as are tastes in food or music. Nonetheless, the bottom line is that humans are not fundamentally logical; their behaviors are driven by emotion. Our thinking helps us get to desired ends, but why do we desire those ends?
In his youth, Hume devised what became known the "IS-OUGHT" problem, describing it as follows:
QUOTE:
In every system of morality, which I have hitherto met with, I have always remarked, that the author proceeds for some time in the ordinary way of reasoning, and establishes the being of a God, or makes observations concerning human affairs; when of a sudden I am surprised to find, that instead of the usual copulations of propositions, is, and is not, I meet with no proposition that is not connected with an ought, or an ought not.
This change is imperceptible; but is, however, of the last consequence. For as this ought, or ought not, expresses some new relation or affirmation, 'tis necessary that it should be observed and explained; and at the same time that a reason should be given, for what seems altogether inconceivable, how this new relation can be a deduction from others, which are entirely different from it.
END_QUOTE
Hume was talking about "moral reasoning", a term he confusingly used in multiple ways. In his broadest sense, moral reasoning was just the balancing of "good" and "bad"; a discussion between Alice and Bob on where they want to eat lunch is, by that definition, a moral argument. In such terms an ethical argument, about "good" and "evil", "right" and "wrong", is a strong case of a moral argument.
Hume got a lot of flak over the IS-OUGHT problem -- and in his maturity, he became much more circumspect about it. Actually, the IS-OUGHT problem isn't really a problem; all Hume meant was that facts don't tell us what we want, they just tell us what the options are. Given a number of restaurants where Alice and Bob can eat lunch -- with considerations such as distance, expense, and quality being roughly equal -- then the discussion renders down to: "OK, so what do we feel like eating?"
Suppose we build a perfectly logical robot: left to itself, it would do nothing at all, it wouldn't even have an instinct for self-preservation. We don't build machines with any more intent to protect themselves than we choose to give them; in fact, when we build smart munitions, they're designed to destroy themselves. Our instincts are not reasoned, they're just what we're built with, and we would similarly have to build instincts into the robot -- above all, to: "Do what you're told."
Although practical, legal, and safety concerns mean there are orders it would not follow -- more on that later -- it would otherwise do what it was told. It would reason out how to do it, but not question what it was told to do. What do humans tell it to do? Whatever they want it to do, and the robot will not be concerned about how much sense the order makes. While some humans think things out much better than others, none of them act like perfectly logical robots. There are people who claim to be perfect rationalists; few believe them.
Humans weren't designed according to a blueprint; they evolved. Humans are another species of primate, in general a lot smarter than our other ape relatives, but still very much like them. We may make long-term plans for our lives, but what foods we like, what hobbies we have, what careers we want, who we marry, is all done by feel -- usually subject to prudent considerations, but still done by feel.
Humans have affections, prejudices, humor, ambitions; they get angry, they get bored, they have fun. Humans are nothing like any machines we can make now, have any prospect of making in the foreseeable future, or have any good reason to make. Machines don't do things by feel, because they don't feel anything. On the other side of that coin, since we feel and they don't -- they can't tell us what we want.
BACK_TO_TOP
