
* During the 20th century, researchers acquired a broad understanding of the chemistry of life, opening the door to major advances in biomedicine and biotechnology in the 21st century.

* While physicists and physical chemists were figuring out the details of the atom and molecular bonding, biochemists were gradually unraveling the processes of life. The basic unit of life had been known for centuries to be the "cell"; many microorganisms consisted only of a single cell, meaning that the cell was a self-sustaining entity, and larger organisms consisted of large numbers of classes of similar cells. The cell was seen as a system whose operation might be ultimately understood.
The hunt for the operation of the cell depended on the development of new tools. Before the First World War, an Austrian chemist named Fritz Pregl (1869:1930) developed an ultrasensitive lab balance and other tools for "micro-analysis" of the faint traces of chemicals often found in biosystems. Another important tool, the "ultracentrifuge", was invented by a Swedish chemist named Theodor Svedberg (1884:1971) in 1923. The ultracentrifuge could be used to spin colloids of large biomolecules, causing them to separate in layers by density under the strong forces.
Svedberg's assistant, Arne Wilhelm Kaurin Tiselius, came up with a subtler scheme, "gel electrophoresis", which involved pulling large molecules through a permeable gel under the influence of an electric field, with different kinds of molecules moving at different rates, resulting in their separation.
Well before that, in 1906, a Russian botanist named Mikhail Semenovich Tsvett (1872:1919) had come up with a scheme for separating plant pigments by filtering them down a column of aluminum oxide powder in a tube. He called the scheme "chromatography", but his paper didn't attract much attention. The idea was rediscovered in the 1920s by a German chemist named Richard Willstaeter (1872:1942) and his student, an Austrian named Richard Kuhn (1900:1967). It proved a very useful scheme for separating the chemical constituents of samples of biomolecules.
In 1944, two British chemists, Archer John Porter Martin (1910:2002) and Richard Lawrence Millington-Synge, introduced an improved scheme in which filter paper was used instead of powder, with the method of course referred to as "paper chromatography". Chromatography could be used on either gaseous or liquid samples.
Yet another tool, "X-ray crystallography", emerged in parallel with the new physics, driven by the father-son team of Sir William Henry Bragg (1862:1942) and Sir William Lawrence Bragg (1890:1971). The technique involved shining a beam of X-rays onto a crystal, and then recording the resulting diffraction pattern onto a photographic plate. The diffraction pattern could be used to obtain clues about the structure of the crystalline material.
* Using the new tools, in the late 19th and into the 20th century structures for an increasing number of complicated biomolecules were determined. For example, a German chemist named Richard Willstaeter (1872:1942) deciphered the structure of chlorophyll, a green chemical used by plants to absorb sunlight and drive plant photosynthesis. Work also advanced on synthesis of biologically active chemicals; for example, in 1944 the American chemists Robert Burns Woodward (1917:1979) and William von Eggers Doering (1917:2011) managed to synthesize the drug quinine, used to treat malaria. Woodward would continue to synthesize other important biological molecules. In 1956 he synthesized "reserpine", one of the first synthetic tranquilizers, and in 1960 he synthesized chlorophyll.
At about the same time that quinine was synthesized, an Australian-English pathologist named Howard Walter Florey (1898:1968) and a German-English biochemist named Ernst Boris Chain (1906:1979) isolated an antibacterial drug from mold that they called "penicillin". It was the first of the "antibiotics", and its discovery could be regarded as the beginning of the modern pharmaceutical industry.
The analysis and synthesis of important biological molecules and drugs was parallel by research into the mysteries of metabolism and photosynthesis, through the work of a number of researchers such as Hans Adolf Krebs (1900:1981), who identified a number of important metabolic cycles, and Melvin Calvin (1911:1997), who used radioactive tracers to help determine the paths of photosynthesis.
* The proteins had long been recognized as biological structural elements, and as mentioned had been known since early in the 19th century to be made up of chains of amino acids, but proteins were so complicated that it was hard to determine their complete structure. Early in the 20th century, a German chemist named Emil Fischer (1852:1919), who had previously made a name for himself through a masterful analysis of the chemistry of simple sugars, turned his attention to proteins, showing that the amino acids in proteins were chained together by a "peptide bond" -- the name derived from the Greek word for "digest", since he believed that proteins broke down into such chains when digested. By 1907, he had linked 18 amino acids together to come up with a "polypeptide chain" that seemed to be a simple protein, though it was clearly a "toy" compared to the larger proteins found in nature. We know today that the "hemoglobin" molecule, one of the essential components of blood, has 550 amino acids -- and it is a small protein.
The development of chromatography provided an excellent tool for determining the types and ratios of different amino acids in a particular protein chain. In 1953, following eight years of work, the English chemist Frederick Sanger (1918:2013) managed to determine the chain structure of the protein "insulin", which had 50 amino acids. Soon the structures of other proteins were being determined, and proteins were being synthesized, with insulin synthesized in 1965.
Simply determining the order of amino acids on the polypeptide chain of a protein was not enough to describe the protein, however. The chain folded up on itself in a complicated three-dimensional pattern, held together by weak hydrogen bonds. If a protein was weakly heated, these hydrogen bonds would be disrupted, with the "denatured" protein losing many of its properties. Linus Pauling suggested, correctly, that some of the simpler proteins, such as those that provide structural elements of skin and fibrous tissue, might feature a polypeptide chain coiled up in a "helix" or "spiral staircase" arrangement, held together by weak hydrogen bonds.
Pauling also suggested that more complicated protein structures had structures with a helical influence, which was demonstrated in 1960 when the Australian-British chemist Max Ferdinand Perutz (1914:2002) and the English chemist John Cowdery Kendrew (1917:1997), aided by X-ray crystallography, deciphered the complete structure of the hemoglobin protein, the oxygen-gathering molecule in human blood, and myoglobin protein, the analogue of hemoglobin in muscle tissue.
As far as nucleic acids went, biochemists were able to see that there were two varieties -- "deoxyribonucleic acid (DNA)" and "ribonucleic acid (RNA)" -- but were initially unable to determine their precise function. Careful experiments showed that they were the factors of heredity -- that is, they contained the "blueprints" for the construction and operation of cells and organisms, being organized as sets of distinct "genes".
Just after World War II, the Austrian physicist Erwin Schroedinger (1887:1961) wrote an influential book titled: WHAT IS LIFE? -- that suggested that nucleic acids might use sequential groups of subunits to "code" instructions for the cell, Linus Pauling later suggested that nucleic acids might also have a helical structure. A New Zealander physicist named Maurice Hugh Frederick Wilkins (1916:2004) performed X-ray crystallography on nucleic acids to probe their structure. In 1953, an English physicist named Francis Harry Compton Crick (1916:2004) collaborated with an American chemist named James Dewey Watson (born 1928) to show that nucleic acids consisted of two parallel helixes, like a long ladder twisted around its axis.
The revelation of Crick and Watson opened the door to a deeper understanding of the processes of life. As was detailed in the following decades, DNA provides a "program" for the construction and operation of a cell, with RNA helping to carry out the program. We have now decoded the full DNA "genomes" -- a genome being the aggregate collection of all genes in a cell -- for a large number of organisms, including humans, and have acquired the ability to manipulate the genome. This is not an endpoint; it is merely the launchpad for a massively expanded understanding of the genome.
BACK_TO_TOP* All organisms are known to be made up of one or more "cells", which are self-contained packages that replicate and maintain their own existence. The cell is known to be made up of several classes of components:
The cell is not a static entity. Its machinery is always in operation, with metabolic processes keeping the cell alive and active. Plant cells also perform photosynthesis to support their life processes, and indirectly support the life processes of all other life-forms on Earth.
There are two general classes of cells, "prokaryotes" and "eukaryotes". Prokaryotes include bacteria and the superficially similar "archaea", once called "archaebacteria", both of which look like bags of biomolecules and lack distinct internal "organelles". Eukaryotes include the single-celled "protists", as well as all plants, fungi, and animals. Compared to prokaryotes, eukaryotes are much larger and have much more elaborate structures -- including a distinct central "nucleus" containing the nucleic acids, as well as a number of specialized organelles. Some of these organelles contain their own simple nucleic acid codes; it is believed that eukaryotes evolved by the collaborative combination of different prokaryotes. The sections below detail the components of the cell.
* The body's proteins make up about half the dry weight of animals, with humans featuring about 30,000 different types of proteins. They are all polymer chains of "amino acids", which are organic molecules that can be thought of as a combination of amines and organic acids, with an amino (NH2) group on one side of a carbon atom and a carboxyl (COOH) group on the other.
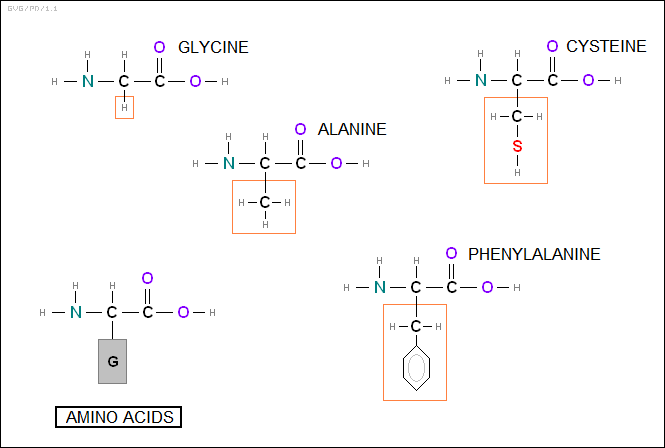
The central carbon atom has a side group that varies depending on the amino acid. The side chains vary in complexity, some of them being much larger and more elaborate than the amino acid core. Human proteins use 20 different amino acids; the exact formula for them is of no great importance here, but it is useful to know their names:
_____________________________________________________ alanine (ala) leucine (leu) arginine (arg) lysine (lys) asparagine (asn) methionine (met) aspartic acid (asp) phenylalanine (phe) cysteine (cys) proline (pro) glutamic acid (glu) serine (ser) glutamine (gln) threonine (thr) glycine (gly) tryptophan (trp) histidine (his) tyrosine (tyr) isoleucine (ile) valine (val) _____________________________________________________
Each chain of amino acids is linked together by "peptide bonds", which are connections between the amino group on one amino acid to the carboxyl group on another.
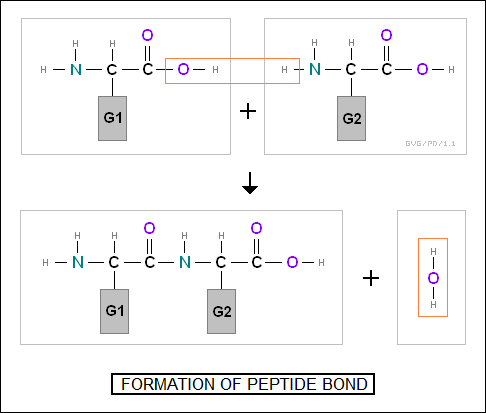
The polypeptide chain of amino acids makes up the "primary structure" of a protein, but the interactions between the units of the chain cause it to fold up in complicated ways. The folding will involve certain general "secondary structures", such as the "alpha helix" or "beta pleated sheet", and in some cases will involve a higher-level "tertiary structure".
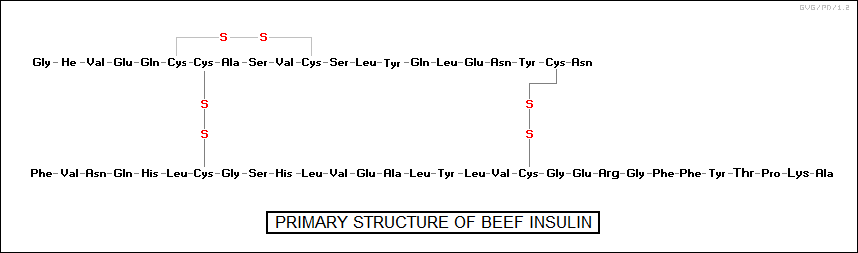
These tertiary structures are due to the fact that some of the side chains of the amino acids in the protein are negatively charged and some are positively charged, resulting in the weak linkages that coil the protein chain up on itself. In addition, the amino acid cysteine, which has a CH2SH side group, can link up with another cysteine on the chain to form a strong "disulfide bond", often found in stiff structural proteins. Some proteins actually consist of multiple chains working together, with such configurations said to have a "quaternary structure".
While it is relatively straightforward (at least with modern technology) to determine the primary structure of proteins, determining their high-level structures can be very difficult, requiring massive amounts of computing power. Incidentally, it is these high-level structures that account for the somewhat unusual tendency of liquid proteins such as egg white to become solid on heating: the heating unwinds or "denatures" the structure of the proteins and the resulting solid tangle can't ever be put back into its original order.
* There are two classes of proteins: fibrous proteins and globular proteins. Fibrous proteins include:
The globular proteins include:
Globular proteins also can form up into tiny "microtubules" that provide connectivity and structural reinforcement in cells, and also help make up the threadlike "cilia" on the surface of some microorganisms. The microtubules are formed as a coil of two proteins, appropriately named "alpha & beta tubulin".
The following table gives the relative sizes of various proteins, listing the number of amino acids in the protein, the molecular weight of the protein, and the number of chains that make up the protein:
protein amino_acids molecular_weight chains __________________________________________________________________ insulin (hormone) 51 5,700 2 cobra venom toxin 62 7,000 1 myoglobin 153 16,900 1 keratin 204 21,000 1 hemoglobin 574 64,500 4 gamma-globulin antibody 1,250 150,000 4 collagen 3,000 300,000 3 __________________________________________________________________
Some proteins are commercially important for medical use -- insulin being one of the most prominent examples. In some cases, insulin also being one of them, it is possible to extract the valuable proteins from animals. However, in modern times bioengineering techniques can be used to modify organisms to produce desired proteins. The "classic" approach is to insert the genetic information to produce a particular protein into the human colon bacterium, Escherichia coli, with the resulting bacterial cells cultivated, collected, and purified into the desired protein. Other work has been done to genetically modify goats to produce valuable proteins through their milk, chickens to produce them through their eggs, and tobacco plants to produce them through their leaves.
* The lipids are distinct from other types of organic compounds in that they won't dissolve in water, but will dissolve in alcohol or other organic solvents. There are several categories of lipids.
The triglycerides -- fats and oils -- were mentioned in the discussion of organic chemistry. They are used for the body's energy storage, providing twice as much energy per mass as carbohydrates or proteins. The most common fats are the "fatty acids", which are combinations of glycerol and long-chain carboxylic acids. Fatty acids include:
arachidic acid (from peanut oil): CH3(CH2)18-COOH butyric acid (from coconut oil): CH3(CH2)2-COOH stearic acid (from animal and vegetable fats): CH3(CH2)16-COOH oleic acid (from corn oil): CH3(CH2)7=CH(CH2)7-COOH
Notice that the first three fatty acids are unsaturated, while oleic acid, with its double bond, is saturated.
The "phospholipids" are a bit like fatty acids, also being esters of glycerol, but they only have two fatty acid chains, the third chain being in the form of a phosphate-based group. This results in a molecule with a nonpolar end -- the dual fatty acid chains -- and a polar head -- the phosphate-based group.
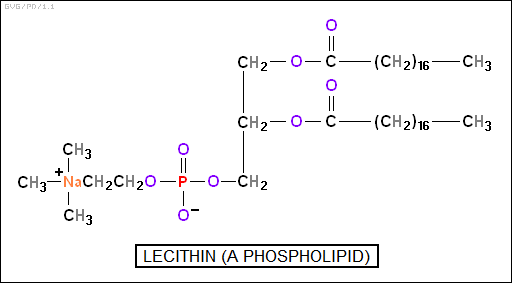
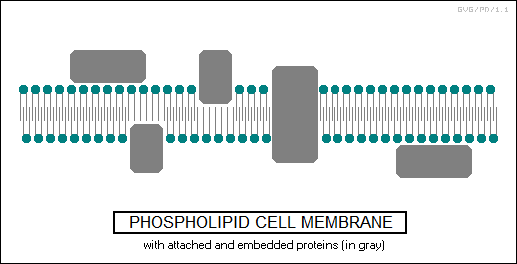
Phospholipids are used to form cell membranes, forming a "bilayer" -- a dual layer with the polarized heads on the surfaces. The cell membrane may feature embedded proteins -- sometimes running through the membrane, operating as a selective pore -- or proteins may loosely adhere to the polar surface.
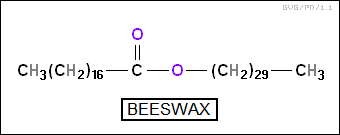
The "waxes" are also esters, but unlike fatty acids and phospholipids they are based on simple alcohols, not glycerol. They are secreted as protective waterproof coatings on plant leaves and the skin of animals.
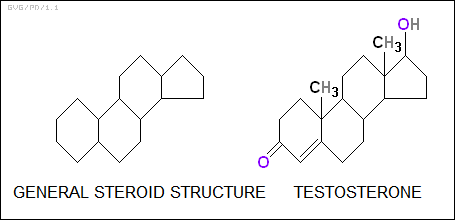
The "steroids" are built around a characteristic structure of four merged carbon rings. They include a number of key hormones, for example estrogen and testosterone, the female and male sex hormones respectively, as well as cholesterol, which contributes to heart disease, and the skin poisons of some species of toads. Some steroids found in human skin turn into vitamin D after exposure to sunlight.
* The carbohydrates are organic molecules with a general formula of Cm(H2O)n, hence the name, though the early idea that they were "hydrates"-- actually incorporating water molecules -- didn't pan out. As mentioned, they serve as both cellular energy sources and structural elements.
There is a hierarchy of carbohydrates. At the bottom are the simple sugars, or "monosaccharides", which are simple ring compounds including "fructose (C6H12O6)" and in particular "glucose (C6H12O6)", which is one of the primary energy fuels in the human body. (Although fructose and glucose have the same general formula, they have different structures -- fructose is based on a five-carbon ring, glucose on a six-carbon ring.)
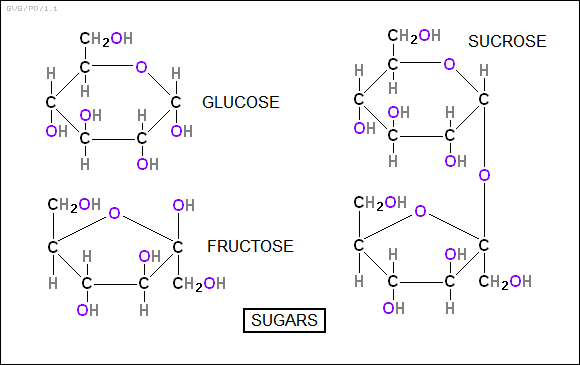
Two simple sugars linked together to form "dissacharides", the most familiar being "sucrose (C12H22O11)" -- ordinary table sugar. Two other common dissacharides" are "maltose", derived from malt, and "lactose", derived from milk.
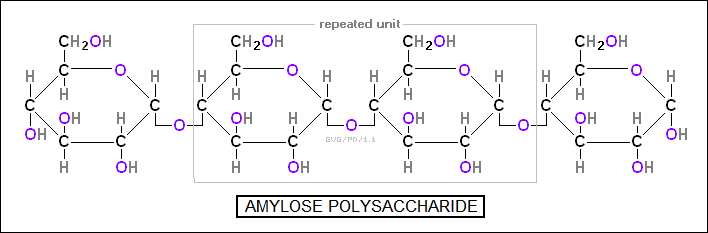
Long chains of simple sugars form "polysaccharides", which are either used as fuel storage -- in the form of "starches" such as "amylose" for plants or the similar "glycogen" for animals, both a chain of about 25 units -- or for structures -- in the form of "cellulose", a chain of 100 to 200 units of six-carbon sugars. Cellulose makes up plant cell walls in combination with "hemicellulose" -- similar to cellulose but is based on five-carbon sugars -- along with a reinforcing material known as "lignin", a messy crosslinked structure of aromatic hydrocarbons. Lignin is particularly common in woody plants. The external "exoskeletons" of insects, crabs, and the like is made of "chitin", a polysaccharide along the lines of cellulose.
* The nucleic acids provide central control over the cells in our body. All the cell's components are assembled and ultimately controlled by a molecular "program" in the form of "deoxyribonucleic acid (DNA)", assisted by "ribonucleic acid (RNA)". DNA and RNA are in the form of double-chain molecules, build up of three classes of molecules.
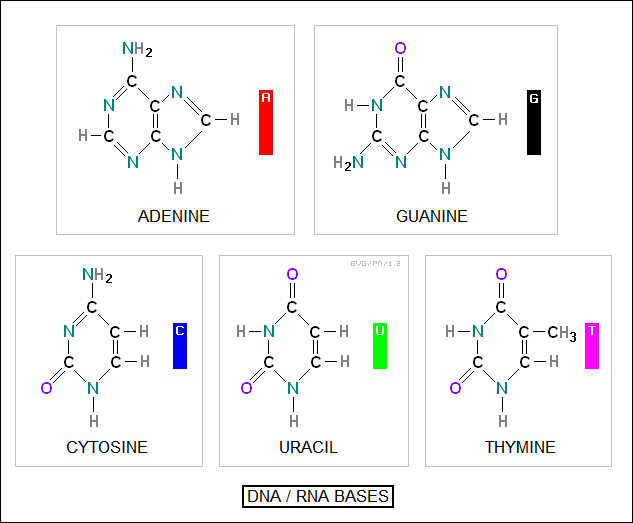
The core of a chain is built around a set of four "nitrogenous bases" -- there's actually five different bases, with one differing between DNA and RNA:
adenine (A) guanine (G) thymine (T) in DNA and uracil (U) in RNA cytosine (C)
It is the arrangement of these bases that provides the information in DNA. Each base is linked to a sugar molecule that helps form the chain structure. The sugar is "deoxyribose" in DNA and "ribose" in RNA.
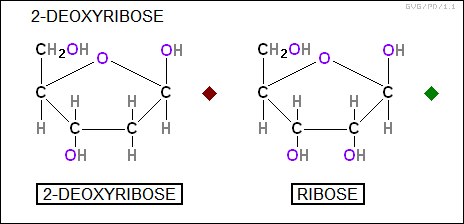
The sugars form the links in the chain, being connected by phosphate (PO4) groups:
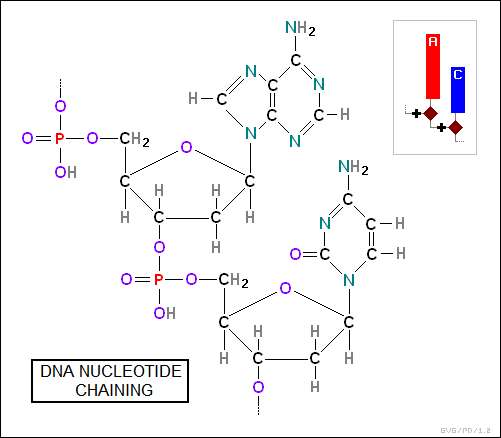
A base, sugar, and phosphate form up a "nucleotide group". Each of the two chains in a DNA / RNA strand are made up of a sequence of such groups. The two chains are linked to each other by weak hydrogen bonds between the bases, with the bases matching up in a "complementary" fashion as follows:
The primary function of DNA is to "code" the production of proteins. The DNA chain is organized in "triplets" or "codons" of bases, coding a particular amino acid in a protein chain as follows:
_____________________________________________________________________ ala: GCU GCC GCA GCG leu: UUA UUG CUU CUC CUA CUG arg: CGU CGC CGA CGG AGA AAG lys: AAA AAG asn: AAU AAC met: AUG asp: GAU GAC phe: UUU UUC cys: UGU UGC pro: CCU CCC CCA CCG glu: GAA GAG ser: UCU UCC UCA UCG AGU AGC gln: CAA CAG thr: ACU ACC ACA ACG gly: GGU GGC GGA GGG trp: UGG his: CAU CAC tyr: UAU UAC ile: AAU AUC AUA val: GUU GUC GUA GUG START AUG STOP UAG UGA UAA _____________________________________________________________________
A particular DNA strand may encode a number of proteins, with a section encoding a single protein making up a gene, and marked out by the START and STOP sequences listed above.
Protein synthesis involves DNA, RNA, enzymes, and a cellular organelle called the "ribosome". Under the control of enzymes, a DNA strand is split in half down the middle, and then forms a matching half-strand of RNA. This "messenger RNA (mRNA)" then leaves the cell nucleus and links to a ribosome. The ribosome scans along the mRNA half-strand, obtaining amino acids tagged by short strands of RNA called "transfer RNA (tRNA)", "translating" the original DNA sequence into a chain of amino acids to form a protein. Once complete, the protein then spontaneously coils into its final structure.

The half-strand of mRNA is called a "sense" half-strand because its nucleotide sequences -- CAA CCC AAU CUG -- define the amino-acid sequence in the final protein. The matching half-strand in the original DNA -- CAA CCC AAT CTG -- is similarly called the "sense" strand, while the complementary or "mirror" half-strand in the DNA -- GTT GGG TTA GAC -- is called the "antisense" half-strand. The sense DNA strand can be regarded as something like a film photograph print, with the antisense DNA strand being a negative, which is used to create the mRNA photo print.
In creation of new cells, the DNA in the cell nucleus also must "replicate", being split down the middle and reformed into two complete chains using an enzyme known as a "DNA polymerase". Errors can occur during the replication process, or sometimes due to damage to the DNA itself by radiation or other factors. These "mutations" can be disastrous, for example when mutations cause cells to replicate wildly as cancers. However, by the odds mutations are generally harmless, and in some cases mutations can be beneficial to an organism.
Incidentally, in many viruses -- the influenza virus being a good example -- the viral genome is RNA, not DNA. The two work about the same as far as coding goes, but RNA is less stable than DNA, the result being that RNA viruses tend to undergo mutations more readily than DNA viruses. The mutability of RNA viruses tends to quickly produce new strains that can evade the body's immune defenses.
* Applications of genetic technology fall into two categories: analysis and modification. With the development of advanced genomic sequencing technology, ever-increasing numbers of genome sequences -- of significant plants and animals, as well as humans -- have become available. The sequences of plants and animals have permitted a far more accurate understanding of their evolutionary ancestry, and also are useful for breeding improved crop plants and domestic animals. Databases of human genomes are becoming a significant tool in public health.
Whole-genome sequencing is powerful, but laborious, and overkill for many applications. Useful analysis can be provided by examination of the presence or absence of various sets of "marker" sequences in the genome -- the markers allowing identification of the genome of a particular individual, or the ethnic derivation of that individual, and possibly providing hints to potential health problems.
Another useful innovation in genetic analysis is the "DNA microarray" or "DNA chip" -- a slide, usually glass, marked using micro-fabrication techniques with a grid of samples of different DNA fragments that can match to target DNA sequences. A sample of DNA to be tested is broken down into fragments, the fragments being tagged with a fluorescent molecule, and then applied to the DNA chip. The chip is then washed, removing all the fragments except those that stick to cells, with the chip scanned by a laser to see which cells fluoresce, identifying a match. The DNA chips have proven useful for identifying toxins, pathogens, and cancer genes; new uses are continuously being found for them.
Early work on DNA modification was laborious, with a focus on "recombinant DNA", meaning DNA obtained from different organisms -- genes being clipped out of genomes with "restriction enzymes", then reassembled into a new gene. One popular trick with recombinant DNA was to splice a phosphorescence gene from jellyfish into other organisms, allowing those organisms to glow in the dark. This was done as a research tool, and sometimes just for fun.
Not everyone thought it was funny, with such "transgenic" organisms popularly regarded as a threat, with governments moving to regulate them. Transgenic organisms are still around, but interest has moved on to subtler genetic technologies. Some years back, biologists discovered an odd feature in the genomes of some bacteria that they described as "clustered, regularly interspaced short palindromic repeats (CRISPR)". Bacteria use them to make little bits of RNA, with the CRISPR RNA binding to a piece of DNA with a complementary sequence. An enzyme named "Cas9" recognizes the structure made when a CRISPR RNA binds to a piece of DNA, and reacts by cutting through the DNA at precisely that point.
Bacteria make CRISPR RNAs that recognize the DNA of viruses which infect on them, marking that DNA for destruction by Cas9, and so protecting the bacteria from infection. It is not difficult to synthesize RNAs that target any DNA sequence researchers want; and because of the way that cells repair broken DNA, if they put a new gene into a cell along with the CRISPR-Cas9 system, they can replace the old gene with a new one.
The effect of CRISPR-Cas9 is revolutionary, giving genome researchers something that works like the find-&-replace function on a word processor. Tools based on CRISPR-Cas9 can edit existing genes, with the results impossible to tell from natural mutations, with the frenzy created by transgenic organisms fading out.
* The metabolic processes that keep the cell in operation fall into two categories: "anabolism" or "synthesis", which involves the construction and maintenance of cellular components; and "catabolism" or "destruction", which involves the use of cellular energy sources just to keep the cell working -- for example, providing energy to muscle cells to provide motion to an animal. Catabolism also supports body temperature and the degradation of waste products for excretion. When anabolism exceeds catabolism, a life-form grows; when catabolism exceeds anabolism, the life-form feeds off its own reserves and tissues, to gradually run down and die.
The anabolic "pathways" begin with simple components called "intermediates" and use enzymes to synthesize a set of "end products", particularly complicated molecules such as carbohydrates, proteins, and fats. The catabolic pathways use a different mix of enzymes to break down complicated molecules into simple ones, producing energy. The fundamental unit of "fuel" for biological processes is "adenosine triphosphate (ATP)", a simple organic molecule with three high-energy phosphate bonds. One phosphate group can be expended, resulting in "adenosine diphosphate (ADP)"; expending another yields "adenosine monophosphate (AMP)".
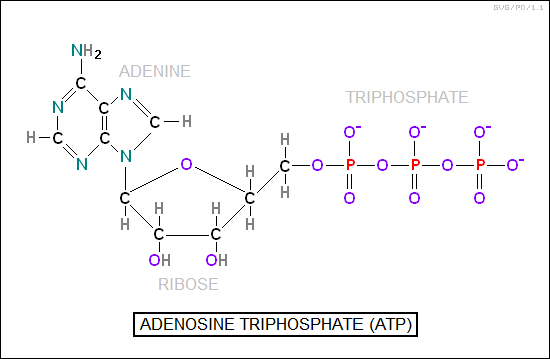
The metabolic system is extremely complicated. It is not only controlled at the cellular level, it is also controlled at an overall level by the nervous system (in animals), as well as hormones -- "chemical messengers" -- released by the pituitary and adrenal glands. Inputs are amino acids from the digestion of proteins; carbohydrates, mostly obtained from digestion in the form of glucose; plus glycerin and fatty acids. Amino acids are synthesized into proteins; glucose is used for energy, with any surplus first converted to starches and the surplus above that to fats; and fats are incorporated into organism structures, with the surplus also stored for lean times.
Metabolic processes produce carbon dioxide and water as waste, with the carbon dioxide exhaled and the water excreted, carrying with it other waste products, indigestibles, and toxins rejected by the digestive system. Trace vitamins are needed to keep the system working.
* Some metabolic processes are consumers of energy, while others are producers of energy -- with the important fine print that the energy has to be obtained from food in the first place. It is the photosynthesis of plants that drives the entire food chain, obtaining energy from the Sun and converting it into fuel and plant structure. At a high level, it is a seemingly simple process, in which carbon dioxide and water are converted into oxygen and the sugar glucose, along with some water:
6CO2 + 12H2O --> C6H12O6 + 6O2 + 6H2O
The glucose can then be converted into cellulose, the structural material that makes up the cell walls. Excess glucose is converted into starch and other carbohydrates, once again to be stored for lean times.
The chemical formula given above is just a "black box" description of photosynthesis, showing the inputs and outputs but not detailing the highly complicated parts in between. Photosynthesis in plants is performed by a cellular organelle named the "plastid" or "chloroplast", with a few dozen in each plant leaf cell. Like the mitochondrion, the chloroplast has its own genome and clearly had a free-living prokaryotic ancestor. The chloroplast is oval-shaped and stores what looks like a stack of disks, each of which is filled with chlorophyll, a green pigment that is central to the photosynthetic process, as well as other "accessory" pigments, plus enzymes and other molecules needed to support photosynthesis.
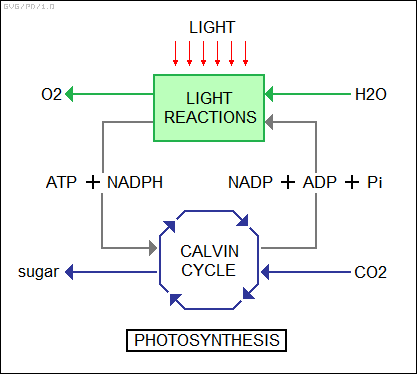
The actual chemical reaction is very complicated, but in broad sweep it consists of two stages:
* While this discussion describes photosynthesis in plants, it also occurs in some bacteria, most notably the "blue-green algae". Since prokaryotes don't have distinct organelles, photosynthetic bacteria don't have chloroplasts, instead containing chlorophyll in folds of their surface membranes called "chromatophores". Some of the archaea also perform a variation on photosynthesis, though instead of using water they use hydrogen sulfide (H2S) and produce sulfur instead of oxygen. There are those who suspect that life got started around sulfurous volcanic vents and that these archaea are the distant descendants of the first true living organisms.
* Along with a discussion of the primary biomolecules -- proteins, lipids, carbohydrates, nucleic acids -- it is worthwhile to consider the class of biomolecules referred to as "vitamins", since the term is in such wide usage.
Vitamins are used by the body to synthesize enzymes, hormones and other chemical necessities. Humans need 13 vitamins to survive; they are all relatively simple organic molecules, with a few dozen carbon atoms at most, featuring ring and chain structures. Vitamins, also called "micronutrients" since they are only required in minute quantities, can be grouped in two categories:
Nutritionists say that it's better to get vitamins through food, the main reason being that the vitamins in fruit, vegetables, and so on also include large numbers of other "phytochemicals" -- plant nutrients that aren't essential for life, but seem to boost health. These phytochemicals include carotenoids in carrots and tomatoes, isothiocyanates in broccoli and cabbage, and flavonoids in soy, cocoa and red wine. Taken together, vitamins and phytochemicals seem to have much more effect than they do when taken individually.
Nutritionists do recommend that healthy adults take a multivitamin pill and extra vitamin D if they don't get much sun. There is debate over the usefulness of large doses of other vitamins -- overdoses of vitamin A are known to be hazardous -- but folic acid (AKA vitamin B9) is recommended for pregnant women to prevent birth defects, vitamin B12 supplements are useful for people over 50 because it gets harder to absorb the vitamin in the digestive tract, and AIDS patients can benefit from multivitamins, since they boost immunity. Ironically, most of the people who take multivitamins are the affluent and health-conscious, and are generally the ones who need them the least.
* A second class of simple biomolecules are the "opsins", which are photosensitive dyes used for vision. They consist of a small protein chain attached to a variant of the vitamin A molecule. Minor variations in the amino acid structure make the opsins sensitive to different colors of light -- humans have three opsins, for red, green and blue. Most other mammals only have two and see in two colors, but birds and some other animals have four and can see into the ultraviolet in some cases. There is a related molecule named "rhodopsin" that is not very color-sensitive but is very light-sensitive. It is used for night vision; nocturnal (night living) and deep sea creatures often only have rhodopsins, no opsins.
* A third interesting minor class of biomolecules are the "semiochemicals", which are "messenger molecules" that send a message from one organism to another. The semiochemicals consist of the "allomones", "kairomones", and the well-known "pheromones".
The allomones provide an advantage of some sort to the organism that produces them. Antibiotics -- chemicals that attack bacterial infections -- were famously discovered in molds that killed off bacterial pathogens. Nicotine is produced by tobacco plants, not to gratify smokers, but to discourage caterpillars from eating the plants, in other words acting as a natural insecticide. The "perfumes" of sweet-smelling flowers act as attractants to pollinators such as bees.
The kairomones provide an advantage to the species that detects them, not the species that produces them. In some cases, allomones and kairomones are one and the same thing -- the perfumes of flowers are allomones to flowers and kairomones to bees. In other cases, kairomones are smells produced by an organism that its adversaries have learned to recognize -- for example, some marine molluscs can smell a starfish nearby and make an escape.
Pheromones are messages sent between members of the same species:
Humans have long leveraged off attractants and sex pheromones to produce perfumes -- though in modern times, scent manufacturers have generally turned to direct synthesis of odors, instead of laboriously extracting them from flowers or the musk glands of animals. The old-fashioned reliance on nature is cost-effective for production of expensive, low-volume perfumes, but the bulk of the industry's production is focused on scents for air fresheners and laundry detergents.
Scent manufacturers still rely on nature for inspiration. "Headspace" sampling was invented in the 1970s and is now being widely used. The technique involves obtaining samples in sealed jars, then later releasing the odor and passing it through a charcoal or silica filter to catch all the organic molecules. The molecules are then sorted out with a gas chromatograph, and tested by a professional sniffer to see if they are valuable. Once screened, the scents are filed in a database for future reference.
BACK_TO_TOP